
IAR Embedded Workbench for Armは、NEONテクノロジーに対応した自動ベクトル化コンパイラをサポートしています。本稿では、組込みNEONテクノロジーを含む新たなArm Cortex-A設計に対し、自動ベクトル化を活用する方法について説明します。
高性能化と低電力化に向けて限りない追求が続く中、半導体メーカーは、シリコンの微細化を推し進めることで、ムーアの法則の限界に挑戦しています。しかし、モバイルデバイスのバッテリ寿命には限りがあることから、半導体製造プロセスにおいて消費電力がプロセッサの最大動作速度を制限する重要な要因として以前にも増して認識されるようになってきました。これは、より高速な製造プロセスの限界域では、消費電力と周波数が非線形の関係となり、動作周波数を高くすると消費電力が指数的に増加するためです。この問題に対処するために半導体IPサプライヤやチップメーカーは、動作速度をできる限り抑えて消費電力とダイサイズへの影響を最小限にすると同時に、マイクロアーキテクチャの面でさまざまな改善を図ることで、プロセッサコアの性能を大幅に向上させてきました。このような機能強化の流れの1つが、SIMD計算ユニットを使用したデータ並列化とベクトル処理の促進です。
SIMDとはSingle-Instruction/Multiple-Data(単一命令複数データ)のことであり、その基本的な概念は、複数のデータパス(レジスタ/メモリ)に同時に作用する特定の機械語命令を使うことで、多数の逐次計算を並列に組み合わせるというものです。SIMDによる並列処理は新しい概念ではなく、1970年代中頃には既にCray-1スーパーコンピュータに採用されていました。他の従来型マイクロコンピュータアーキテクチャでは、算術演算ユニットを1つ使って、1ペアのオペランドに対して一度に1命令ずつ逐次実行するものでした。このようなプロセッサはSISDアーキテクチャ、すなわちSingle-Instruction/Single-Data(単一命令単一データ)アーキテクチャと呼ばれます。SIMD命令は、計算集約型のデジタル信号処理を行う多くのマルチメディアアプリケーションにおいて、その性能を大幅に向上させる可能性を秘めています。
Arm Cortex-Ax NEONの概要
Armv7アーキテクチャでは、Armv-7AおよびArmv7Rプロファイル用にAdvanced SIMD(NEON)拡張命令セットが採用されました。NEONは64/128ビットという広いビット幅を持つSIMDデータ処理アーキテクチャで、同一命令によって複数のデータ要素を並列処理する命令グループを定義することで、デジタル信号処理アプリケーションの処理速度を向上させます(図1)。
この命令は、64ビットのD(ダブルワード)ベクトルレジスタと、128ビットのQ(クワッドワード)ベクトルレジスタに保存されたベクトルデータ要素を処理できます。これらのレジスタベクトル要素は同じデータタイプで、符号付きまたは符号なしの8ビット、16ビット、32ビット、または64ビット整数データとすることができます。NEONは32ビットの単精度浮動小数点もサポートしています。
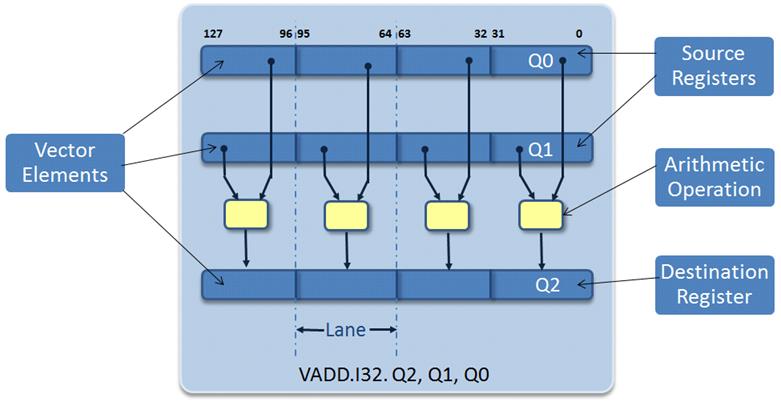
図1:Arm Cortex AのNEONユニット
NEONレジスタバンクは、コアレジスタとは別に、256バイト(または32×64ビット)のレジスタファイルを提供します。1つのレジスタバンクに対して明示的にエイリアス化された2つの見方が存在し(図2)、NEONユニットは、これを32×64ビットのダブルワードレジスタ(D0~D31)、あるいは16×128ビットのクワッドワードレジスタ(Q0~Q15)と見なします。ベクトル命令が適切なレジスタ使用方法を決定するので、ソフトウェアによってレジスタ間で明示的にデータを切り替えたり移動したりすることはありません。
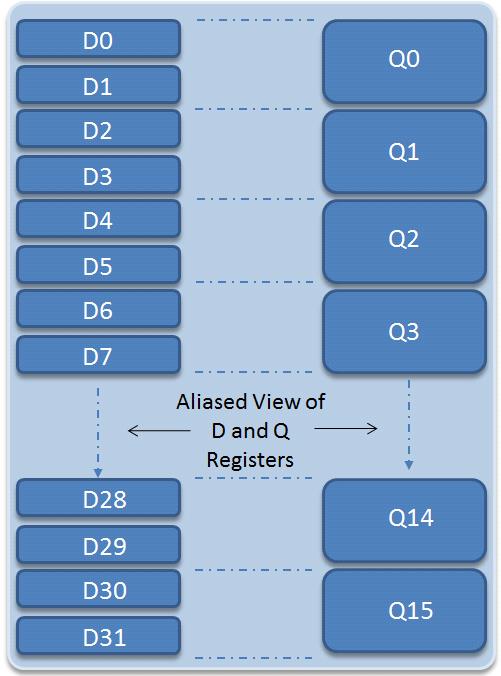
図2: NEONレジスタバンク
データタイプとレジスタサイズに応じて、2、4、8、16個の要素に対して並列に扱うことができます。たとえば32ビット整数に対する操作では4個のデータ要素を並列に扱うことができ、16ビット整数では8個のデータ要素を、さらに8ビット整数では16個のデータ要素を並列に扱うことができます。NEONのベクトル用アセンブリ言語命令の例を図3にいくつか示します。
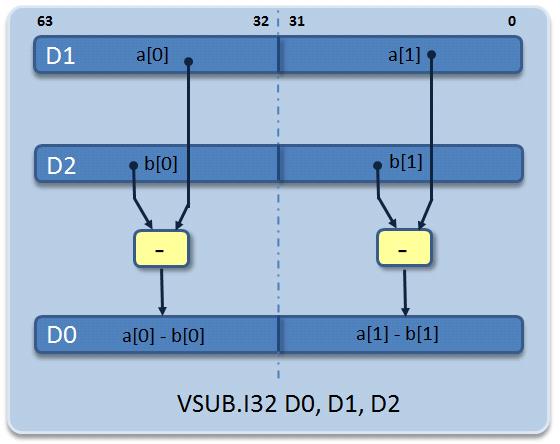
図3:32ビット固定小数点および浮動小数点データによるベクトル乗算命令の例
IAR Embedded Workbench for Armにおけるコンパイラのベクトル化機能
アルゴリズム開発者は、ハンドコードで自らのアセンブリモジュールを記述したり、Armの提供するCコンパイラ組込み関数を使用することにより、さまざまなオプションを備えたNEON命令を最大限に利用しようとする可能性があります。しかし、組込み関数は、多くのアルゴリズムエキスパートにとって使いにくいことが多く、さらには異なるマイクロコンピュータアーキテクチャ間やCコンパイラ間でソースコードを移植できない結果となることもあります。そのため、IAR Embedded Workbench for Armのバージョン7.10では、NEONの利点を容易に活かせるようにベクトル化がサポートされました。ベクトル化によって、コンパイラはNEONベクトル命令の利点を活用でき、ユーザは低水準ベクトルアセンブリ言語やコード移植性に関する配慮が不要となります。ベクトル化を自動ベクトル化あるいはオートベクトル化と呼ぶベンダーもあります。
ベクトル化とは?
ベクトル化とは演算速度を最適化する手法であり、一度に1ペアのオペランドの計算を行うスカラー実装を、同時に複数ペアのオペランドに対して同一の計算を行うベクトル実装に変換します。ベクトルはすべて同じタイプのスカラーデータのセットであり、メモリに保存されています。ベクトルに対して算術演算や論理演算を行う場合、ベクトル処理が行われます。そのため、上記のようなコンパイラによるスカラー処理からベクトルコードへの変換のことをベクトル化と呼びます。この変換の際、コンパイラはまずソースコードを分析して一定のループをベクトルアルゴリズムにマップできるかどうかを決定します。次に、それらのスカラーループを要素ブロックに対して算術計算を行うベクトル演算のシーケンスに変換します。
2つの配列a[ ]とb[ ]を加算して、3つめの配列c[ ]を求める下の関数を考えます。
int a[256], b[256], c[256];
void add_arrays()
{
int i;
for (i = 0; i < 256; ++i)
{
c[i] = a[i] + b[i];
} }上に示すfor{ }ループは、256要素の配列を3つ使って、単純にスカラーの加算を行います。デフォルト設定では、ベクトル化による最適化は行わず(もしくは他の何らかのコンパイラ最適化を行い)、コンパイラは以下のアセンブリ命令を生成して配列要素を加算します。要素a[i]はレジスタR4にロードされ、レジスタR5にロードされたb[i]要素と加算されます。加算後に得られた結果c[i]はレジスタR4に保存されます。

上の関数は、NEON命令を使わずに1541サイクルで実行されます。
合計1541サイクル = (256ループ反復 × 6命令) + 5ループ設定サイクル
ここで、上のコード例でベクトル化を有効にした場合、何が起こり、どの程度速度が向上するかを確認しましょう。ベクトル化を有効にした後にコードを再コンパイルすると、生成されるアセンブリコードは次のようになります。

Rxレジスタを使用する通常の算術演算命令は、NEONのDxレジスタとQxレジスタに対して演算を行うベクトル命令に置き換えられています(ベクトル命令は青字で表示)。この場合、これらのベクトル命令は4個の配列要素のロード、加算、保存を同時に行います。最初のループ反復では、Q0とQ1に保存された最初の4個のベクトル要素の加算が行われ、その結果がQ0レジスタに保存されます。
c0= a0 + b0
c1= a1 + b1
c2= a2 + b2
c3= a3 + b3
2回目のループ反復では、Q0とQ1に保存された次の4個のベクトル要素の加算が行われ、その結果がQ0レジスタに保存されます。
c4= a4 + b4
c5= a5 + b5
c6= a6 + b6
c7= a7 + b7
以降、同様の処理が繰り返されます。図4は最初のループ反復におけるVADD.I16命令のデータフローです。
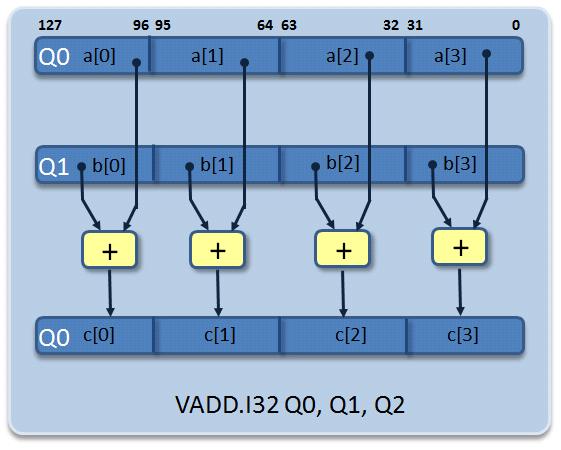
図4:32ビット整数データ要素4個のベクトル加算命令
この場合、ループカウンタの値は256(ベクトル化なし)から64(ベクトル化あり)に減り、256個の配列要素の加算が388サイクルだけで完了します。
合計388サイクル = (64ループ反復 × 6命令/1反復) + 4ループ設定サイクル
つまり、32ビット整数データに対するシンプルな加算アルゴリズムで約400%の性能向上が実現したことになります。一方で、計算に必要な精度が16ビットに止まる場合はどうでしょう。これを、int型の配列からshort型の配列に変更して確認してみます。
shorta[256], b[256], c[256]
add_arrays()
{
int i; for (i = 0; i < 256; ++i)
{
c[i] = a[i] + b[i];
}
}データサイズを半分にする簡単なソースコードの変更によって、ベクトル命令内で処理するベクトル要素の数を倍にすることができます。コンパイルされたアセンブリ命令はこの最適化を裏付けるものです。

この場合、これらのベクトル命令(青字で表示)は8個の配列要素のロード、加算、保存を同時に行います。最初のループ反復では以下のベクトル要素が加算されて、その値がQ0結果レジスタに保存されます。
c0= a0 + b0
c1= a1 + b1
c2= a2 + b2
c3= a3 + b3
c4= a4 + b4
c5= a5 + b5
c6= a6 + b6
c7= a7 + b7
2回目のループ反復では次の8個の配列要素が加算されて、その値がQ0結果レジスタに保存されます。
c8= a8 + b8
c9= a9 + b9
c10= a10 + b10
c11= a11 + b11
c12= a12 + b12
c13= a13 + b13
c14= a14 + b14
c15= a15 + b15
以降、同様の処理が繰り返されます。図5は、最初のループ反復におけるVADD.I16命令のデータフローです。
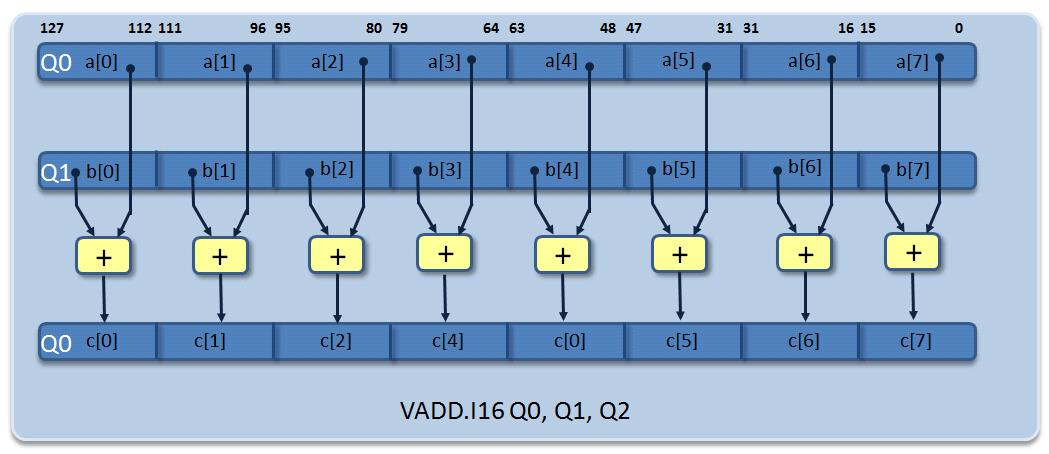
1サイクルあたり8回の16ビット転送と8回の算術演算を実行できるので、ループカウンタの値はさらに減り、反復回数は256(ベクトル化なし)から32(ベクトル化あり)になります。256個の配列要素の加算は、わずか196サイクルで完了します。
合計196サイクル = (32ループ反復 × 6命令/1反復) + 4ループ設定サイクル
このように、4倍(32ビット整数演算)および8倍(16ビット整数演算)の速度向上が、ARM NEON拡張セットを利用するための複雑なソース変更を行うことなく、容易に実現できました。さらに、IAR Embedded Workbenchのベクトル化コンパイラを使用すれば、100%移植可能なコードを維持することが可能です。NEONのベクトル化命令を使用するために、コンパイラ組込み関数や#pragmaを使用するような手法は必要ありません。このコンパイラがNEONベクトル命令を使って、コードを最適化するための面倒な作業をユーザに代わって行ってくれます。
IAR Embedded Workbenchのベクトル化を有効にする
Cortex-A NEONデザインへの自動ベクトル化のサポートは、IAR Embedded Workbench for ArmのIDEプロジェクトオプションを使って簡単に追加できます。その方法を以下に示します。
IDEプロジェクトオプションからベクトル化を有効にする
まず、使用するCortex-AコアがNEON拡張をサポートしている必要があります。サポートの有無は、そのチップのメーカーが、そのCortex-AデバイスにNEONベクトル浮動小数点ユニットを組み込んでいるかどうかによって異なります。A5コアの中にはこのユニットがオプションブロックのものもありますが、A8やA9といった他のコアではすべての機能が組込み済みです。ベクトル化による最適化が可能であることをコンパイラに認識させるために、まず、使用するデバイスがFVPv3とNEONをサポートしていることをコンパイラに知らせます。このオプションは、Project(プロジェクト)> Options(オプション)> General Options(一般オプション)> FPU VFPv3 + NEONで設定します(図6)。このFPU設定がデフォルトになっているCortex-Aコアもあります。
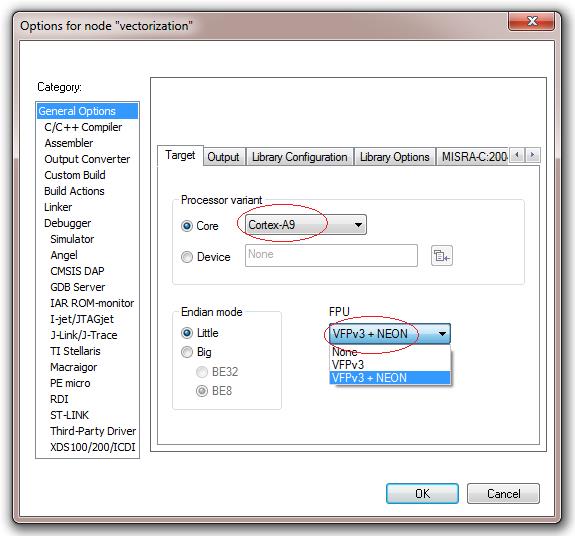
図6:Embedded Workbenchのプロジェクトオプションでベクトル浮動小数点サポートを有効にする
次のステップでは、IDEプロジェクトオプションのC/C++コンパイラカテゴリ画面を表示して、最適化タブ内でベクトル化を有効にします。これは、Project(プロジェクト)> Options(オプション)> C/C++ Compiler(C/C++コンパイラ)> Optimizations(最適化)> Enabled transformations(使用可能な変換)> Vectorize(ベクトル化)(チェックボックス)を選択することによって行います(図7)。この選択により、ループ用のCソースからNEONベクトルアセンブリ言語命令を生成できるようになります。これと同等の機能を持つコマンドラインオプションが–vectorizeです。
重要:ループがベクトル化されるのは、プロセッサがNEONに対応しており、プロジェクトオプションがHigh Level/Speed Optimization(高レベル/スピードの最適化)に設定されている(または-Ohsコマンドライン最適化オプションが使用されている)場合に限られます。
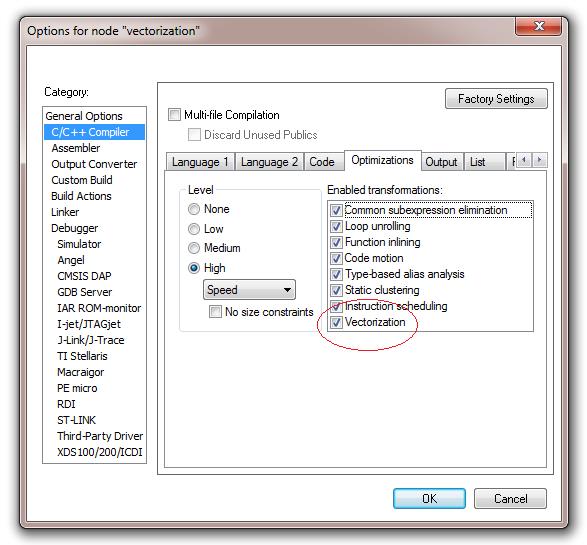
図7:Embedded WorkbenchのプロジェクトオプションでNEONベクトル化を有効にする
ソースファイルレベルでベクトル化を有効にする
IAR Embedded Workbench for ArmのC/C++コンパイラでは、プラグマディレクティブを使用することにより、Cソースファイル内でさらに細かなベクトル化制御を行うこともできます。下に示すように、特定の関数の前で、または特定のループに対してベクトル化を有効または無効にすることができます。
関数の直前:
- #pragma optimize = vectorize
- #pragma optimize = no_vectorize
特定ループの直前
- #pragma vectorize
- #pragma vectorize = never
たとえば、次のようなプラグマディレクティブで、特定のループ用のNEONベクトル命令を有効にします。
#pragma vectorize
for (i = 0; i < 1024; ++i)
{
a[i] = b[i] * c[i];
}結論
Arm Cortex-AのNEON拡張により、かつては専用DSPの領域であったデジタル信号処理アプリケーションを強く意識した機能がArmプロセッサに提供されることになります。NEONにより、低消費電力マルチメディアアプリケーションが得られるメリットは明らかです。NEONユニットの消費電力はArm Cortexコアの整数ユニットと同等なので、チップ上のArmコアの数を増やした場合に比べて、より小さいダイ面積で総消費電力を抑え、より高い性能を実現できます。また、データを並列処理することでプロセッサの使用帯域幅を減らし、より多くのリソースを他のタスクに割り当てることが可能となります。その結果、システム全体の応答時間が向上しバッテリ寿命が延び、NEON対応デバイスへの移行時に、PCBボード面積と全体コストをさらに削減できる可能性があります。
ベクトル化コンパイラを使用してDSP開発を加速できれば、Arm NEONベースの製品は、ユーザの次期設計にとってさらに魅力的なものとなるでしょう。IAR Embedded Workbench for Armのベクトル化による最適化は、非常に簡単に使用できます。これによりコードの移植性が維持され、NEONコプロセッサを使用するためにコンパイラ組込み関数やハンドコードしたアセンブリを使用する必要もなくなります。ベクトル化は設計の複雑さを軽減し、開発時間と市場投入時間を短縮します。是非、このコンパイラをご活用ください。
References
- ARM Limited, Introducing NEON Development Article, 2009,
- M. Anderson, 2011, ARM Neon Instruction Set and Why You Should Care,
- Del Mar North, Neon-Test Code Tutorial, April 2010,
- Incube Solutions Pvt, Ltd., Optimization of Multimedia Codecs using ARM NEON,
- M. Harnisch, Using your C Compiler to expoint NEON Advanced SIMD, 2010,
- G. Mitra, A. Rendell, J, Zhou, Use of SIMD Vector Operations to Accelerate Application Code Performance on Low-Powered ARM and Intel Platforms,
- P. Beckmann, DSP Concepts, 2011, Real Time Audio Processing Capabilities of Microcontrollers, Applications Processors, and DSPs
